TL;DR
- 특정 column 으로 parquet 파일에 대한 쿼리가 많이 발생할 경우 쿼리 속도를 최적화 할 수 있다.
- Parquet query engine 의 predicate pushdown 을 최대한 활용하면 되며
- 이를 위해 해당 column 으로 sorting 된 데이터를 저장하면 된다.
Intro
수십억 레코드가 넘어가는 대용량의 데이터를 parquet 형식으로 저장하면 저장공간과 쿼리속도 측면에서 많은 이점을 가져다 준다.
보통 여기서 말하는 쿼리속도 이점은 "사용할 컬럼만 메모리에 로드" 한다는 점을 말하는데, 좀 더 신경써서 데이터를 저장하면 "사용할 row 만 메모리에 로드" 할 수도 있어 더욱 빠른 쿼리가 가능하다.
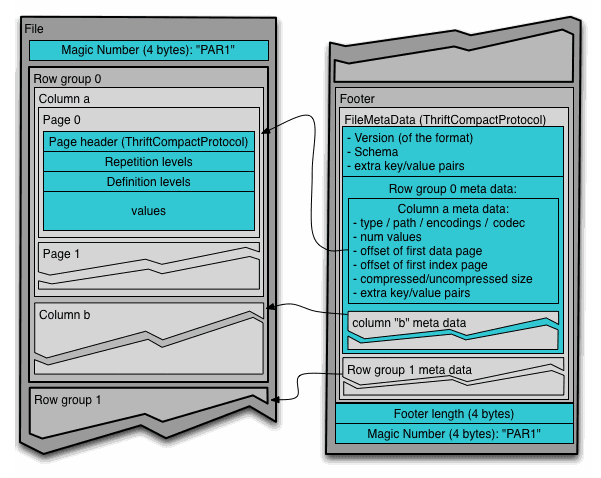
Parquet file structure
parquet 파일의 구조는 아래와 같은 특징을 지니고 있다.
- metadata 가 data 의 뒤에 써 있다. (for single pass writing)
- 일정 크기의 row 가 하나의 row group 에 들어가 있다.
- 각 row group 은 여러 column 으로 구성되어 있다.
- 각 column 은 여러 data page 로 구성되어 있다.
- 각 metadata 엔 statistics data 가 들어가 있다.
Statistics data
Row group, data page 마다 각 컬럼의 statistics 가 포함되어 있다.
/**
* Statistics per row group and per page
* All fields are optional.
*/
struct Statistics {
1: optional binary max;
2: optional binary min;
3: optional i64 null_count;
4: optional i64 distinct_count;
5: optional binary max_value;
6: optional binary min_value;
7: optional bool is_max_value_exact;
8: optional bool is_min_value_exact;
}
Predicate pushdown
Statistics 정보를 이용하면 특정 데이터가 row group or data page 내에 있을 수 있는지 혹은 무조건 없는지 판별할 수 있다.
예를 들어,
filter)
WHERE money > 30
statistics)
Row group1, "money" column
- min : 10
- max : 28
Row group2, "money" column
- min : 15
- max : 42
인 경우, row group1 에는 원하는 데이터가 "무조건 없다"는 걸 알고, row group2 에는 원하는 데이터가 "있을 수 있다"는 걸 알 수 있다.
그렇기에 이 경우 row group2 의 데이터만 메모리로 로드해 필터링을 수행하면 된다.
Parquet file data store strategy
앞선 predicate pushdown 기능을 이용하면 훨씬 빠르게 대량의 데이터를 쿼리할 수 있다.
우선, 주로 쿼리가 발생하는 key column이 있어야 한다. 예를 들어,
- 특정 유저의 segment 만 조회해 분석한다거나 (key column = user_id)
- 특정 시간대의 데이터만 조회해 분석한다거나 (key column = hour)
Predicate pushdown 의 이점을 최대한으로 보면 특정 필터에 해당하는 row group 혹은 data page 의 갯수가 최소가 되고 이를 위해선 각 row group 혹은 data page 의 key column range 가 겹치지 않아야 한다. (혹은 적게 겹쳐야 한다)
BEST
row group 1 column A : min 1 / max 1000
row group 2 column A : min 1001 / max 2000
row group 3 column A : min 2001 / max 3000
...
WORST
row group 1 column A : min 1 / max 3000
row group 2 column A : min 1 / max 3000
row group 3 column A : min 1 / max 3000
...
예를들어 WHERE A = 1487 라는 필터를 걸었을 때 BEST case 에선 row group 2 만 불러오면 되는 반면, WORST case 에선 모든 데이터를 다 불러와야 한다.
결국, 자주 필터를 거는 key column 에 대해 sorting 된 데이터를 저장해야 한다.